pyregexp package#
Submodules#
pyregexp.engine module#

UML of all pyregexp.engine classes.#
Module containing the RegexEngine class.
The RegexEngine class implements a regular expressions engine.
Example
Matching a regex with some test string:
reng = RegexEngine()
result, consumed = reng.match(r"a+bx", "aabx")
- class pyregexp.engine.RegexEngine[source]#
Bases:
objectRegular Expressions Engine.
This class contains all the necessary to recognize regular expressions in a test string.
- match(re: str, string: str, return_matches: bool = False, continue_after_match: bool = False, ignore_case: int = 0) Union[Tuple[bool, int, List[Deque[pyregexp.match.Match]]], Tuple[bool, int]][source]#
Searches a regex in a test string.
Searches the passed regular expression in the passed test string and returns the result.
It is possible to customize both the returned value and the search method.
The ignore_case flag may cause unexpected results in the returned number of matched characters, and also in the returned matches, e.g. when the character ẞ is present in either the regex or the test string.
- Parameters
re (str) – the regular expression to search
string (str) – the test string
return_matches (bool) – if True a data structure containing the matches - the whole match and the subgroups matched (default is False)
continue_after_match (bool) – if True the engine continues matching until the whole input is consumed (default is False)
ignore_case (int) – when 0 the case is not ignored, when 1 a “soft” case ignoring is performed, when 2 casefolding is performed. (default is 0)
- Returns
A tuple containing whether a match was found or not, the last matched character index, and, if return_matches is True, a list of deques of Match, where each list of matches represents in the first position the whole match, and in the subsequent positions all the group and subgroups matched.
pyregexp.lexer module#

UML of all pyregexp.lexer classes.#
- class pyregexp.lexer.Lexer[source]#
Bases:
objectLexer for the pyregexp library.
This class contains the method to scan a regular expression string producing the corresponding tokens.
- scan(re: str) List[pyregexp.tokens.Token][source]#
Regular expressions scanner.
Scans the regular expression in input and produces the list of recognized Tokens in output. It raises an Exception if there are errors in the regular expression.
- Parameters
re (str) – the regular expression to scan
- Returns
the list of tokens recognized in the passed regex
- Return type
List[Token]
pyregexp.match module#
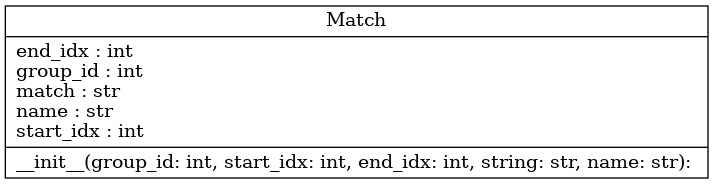
UML of all pyregexp.match classes.#
pyregexp.pyrser module#

UML of all pyregexp.pyrser classes.#
- class pyregexp.pyrser.Pyrser[source]#
Bases:
objectRegular Expression Parser.
Pyrser instances can parse regular expressions and return the corresponding AST.
- parse(re: str) pyregexp.re_ast.RE[source]#
Parses a regular expression.
Parses a regex and returns the corresponding AST. If the regex contains errors raises an Exception.
- Parameters
re (str) – a regular expression
- Returns
the root node of the regular expression’s AST
- Return type
pyregexp.re_ast module#
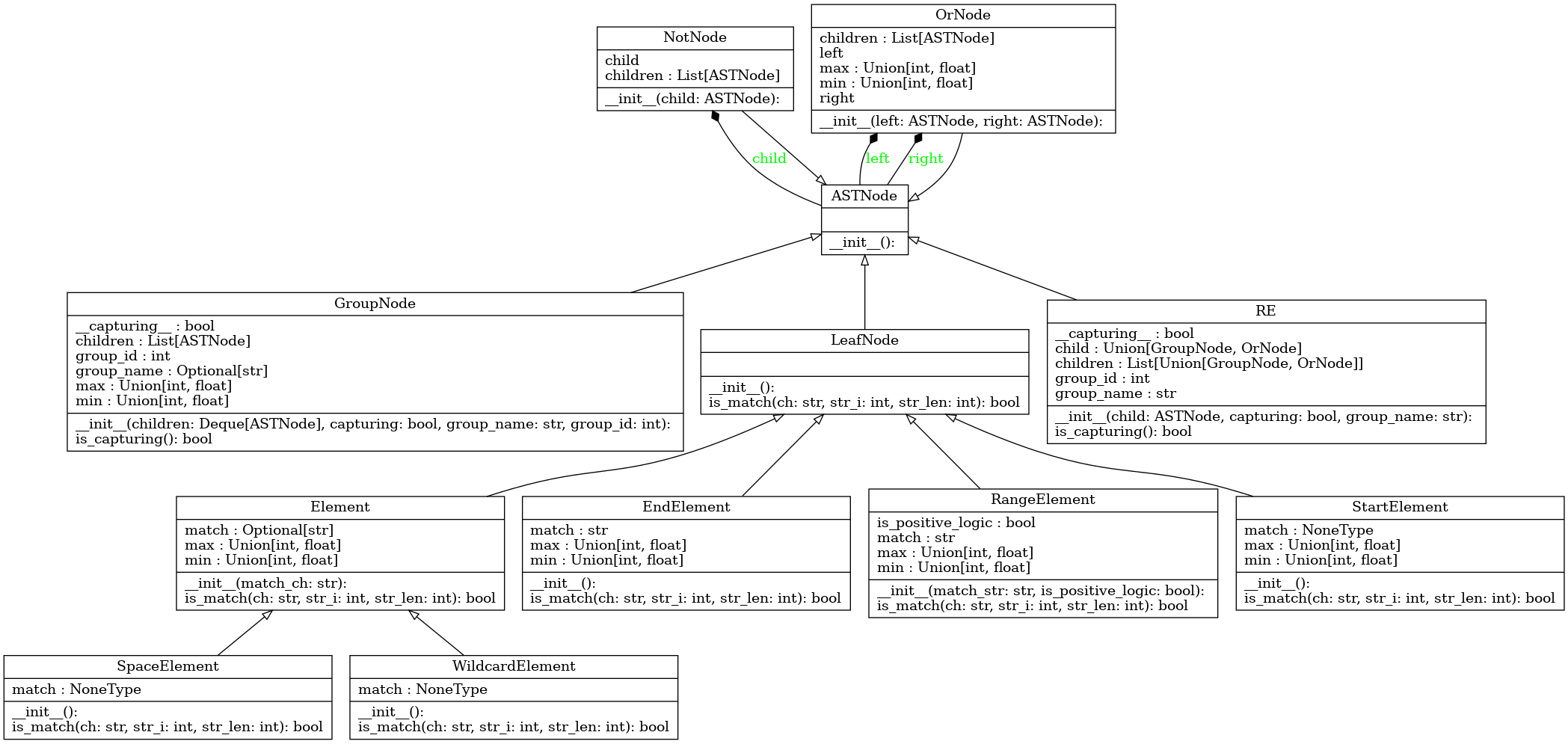
UML of all pyregexp.re_ast classes.#
- class pyregexp.re_ast.ASTNode[source]#
Bases:
objectAST nodes base class.
Abstract Syntax Tree classes hierarchy base class.
- class pyregexp.re_ast.Element(match_ch: Optional[str] = None)[source]#
Bases:
pyregexp.re_ast.LeafNodeAST Element.
Specialization of the LeafNode class. This class models the elements of a regex.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.EndElement[source]#
Bases:
pyregexp.re_ast.LeafNodeAST EndElement.
Inherits from LeafNode and models the match-end-element behavior.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.GroupNode(children: Deque[pyregexp.re_ast.ASTNode], capturing: bool = False, group_name: Optional[str] = None, group_id: int = - 1)[source]#
Bases:
pyregexp.re_ast.ASTNodeAST GroupNode.
Inherits from ASTNode and models the group in a regex.
- class pyregexp.re_ast.LeafNode[source]#
Bases:
pyregexp.re_ast.ASTNodeAST class defining the leaf nodes.
Every leaf node inherits from this class.
- is_match(ch: Optional[str] = None, str_i: Optional[int] = None, str_len: Optional[int] = None) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.NotNode(child: pyregexp.re_ast.ASTNode)[source]#
Bases:
pyregexp.re_ast.ASTNodeAST NotNode.
Inherits from ASTNode and models the not-node behavior.
- class pyregexp.re_ast.OrNode(left: pyregexp.re_ast.ASTNode, right: pyregexp.re_ast.ASTNode)[source]#
Bases:
pyregexp.re_ast.ASTNodeAST OrNode.
Inherits from ASTNode and models the or-nodes, that is the nodes that divides the regex into two possible matching paths.
- class pyregexp.re_ast.RE(child: pyregexp.re_ast.ASTNode, capturing: bool = False, group_name: str = 'RegEx')[source]#
Bases:
pyregexp.re_ast.ASTNodeEntry point of the AST.
This class acts as the entry point for a regular expression’s AST.
- class pyregexp.re_ast.RangeElement(match_str: str, is_positive_logic: bool = True)[source]#
Bases:
pyregexp.re_ast.LeafNodeAST RangeElement.
Specialization of the LeafNode class modeling the range-element behavior, that is that it matches with more than one character.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.SpaceElement[source]#
Bases:
pyregexp.re_ast.ElementAST SpaceElement.
Specialization of the element class to model the match-space behavior.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.StartElement[source]#
Bases:
pyregexp.re_ast.LeafNodeAST StartElement.
Inherits from LeafNode and models the match-start-element behavior.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
- class pyregexp.re_ast.WildcardElement[source]#
Bases:
pyregexp.re_ast.ElementAST WildcardElement.
Specialization of the Element class to model the wildcard behavior.
- is_match(ch: Optional[str] = None, str_i: int = 0, str_len: int = 0) bool[source]#
Returns whether the passed inputs matches with the node.
For example, if the node matches the character “a” and the passed ch is “b” the method will return False, but if the passed ch was “a” then the result would have been True.
- Parameters
ch (str) – the char you want to match
str_i (int) – the string index you are considering
str_len (int) – the test string length
- Returns
represents whether there is a match between the node and the passed parameters or not.
- Return type
bool
pyregexp.tokens module#

UML of all pyregexp.tokens classes.#
- class pyregexp.tokens.Asterisk[source]#
Bases:
pyregexp.tokens.ZeroOrMoreQuantifier ‘zero or more’ token using character ‘*’.
- class pyregexp.tokens.Bracket[source]#
Bases:
pyregexp.tokens.TokenBrackets token.
- class pyregexp.tokens.Circumflex[source]#
Bases:
pyregexp.tokens.NotTokenToken of the negation using ‘^’.
- class pyregexp.tokens.Comma[source]#
Bases:
pyregexp.tokens.TokenToken of a comma.
- class pyregexp.tokens.CurlyBrace[source]#
Bases:
pyregexp.tokens.TokenCurly brace token.
- class pyregexp.tokens.Dash[source]#
Bases:
pyregexp.tokens.TokenToken of the dash ‘-‘.
- class pyregexp.tokens.ElementToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken that are not associated to special meaning.
- class pyregexp.tokens.End[source]#
Bases:
pyregexp.tokens.EndTokenToken using ‘$’ to match end.
- class pyregexp.tokens.EndToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of match end.
- class pyregexp.tokens.Escape[source]#
Bases:
pyregexp.tokens.TokenToken of the escape character.
- class pyregexp.tokens.LeftBracket[source]#
Bases:
pyregexp.tokens.BracketLeft bracke token.
- class pyregexp.tokens.LeftCurlyBrace[source]#
Bases:
pyregexp.tokens.CurlyBraceLeft curly brace token.
- class pyregexp.tokens.LeftParenthesis[source]#
Bases:
pyregexp.tokens.ParenthesisLeft parenthesis token.
- class pyregexp.tokens.NotToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of the negation.
- class pyregexp.tokens.OneOrMore(char: str)[source]#
Bases:
pyregexp.tokens.QuantifierQuantifier ‘one or more’ token.
- class pyregexp.tokens.OrToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of the or.
- class pyregexp.tokens.Parenthesis[source]#
Bases:
pyregexp.tokens.TokenToken of a parenthesis.
- class pyregexp.tokens.Plus[source]#
Bases:
pyregexp.tokens.OneOrMoreQuantifier ‘one or more’ token using character ‘+’.
- class pyregexp.tokens.Quantifier(char: str)[source]#
Bases:
pyregexp.tokens.TokenQuantifier token.
- class pyregexp.tokens.QuestionMark[source]#
Bases:
pyregexp.tokens.ZeroOrOneQuantifier ‘zero or one’ token using character ‘?’.
- class pyregexp.tokens.RightBracket[source]#
Bases:
pyregexp.tokens.BracketRight bracket token.
- class pyregexp.tokens.RightCurlyBrace[source]#
Bases:
pyregexp.tokens.CurlyBraceRight curly brace token.
- class pyregexp.tokens.RightParenthesis[source]#
Bases:
pyregexp.tokens.ParenthesisRight parenthesis token.
- class pyregexp.tokens.SpaceToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of a space.
- class pyregexp.tokens.Start[source]#
Bases:
pyregexp.tokens.StartTokenToken using ‘^’ to match start.
- class pyregexp.tokens.StartToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of match start.
- class pyregexp.tokens.VerticalBar[source]#
Bases:
pyregexp.tokens.OrTokenToken of the or using ‘|’.
- class pyregexp.tokens.Wildcard[source]#
Bases:
pyregexp.tokens.WildcardTokenToken using ‘.’ as wildcard.
- class pyregexp.tokens.WildcardToken(char: str)[source]#
Bases:
pyregexp.tokens.TokenToken of a wildcard.
- class pyregexp.tokens.ZeroOrMore(char: str)[source]#
Bases:
pyregexp.tokens.QuantifierQuantifier ‘zero or more’ token.
- class pyregexp.tokens.ZeroOrOne(char: str)[source]#
Bases:
pyregexp.tokens.QuantifierQuantifier ‘zero or one’ token.
Module contents#

UML of all pyregexp classes.#
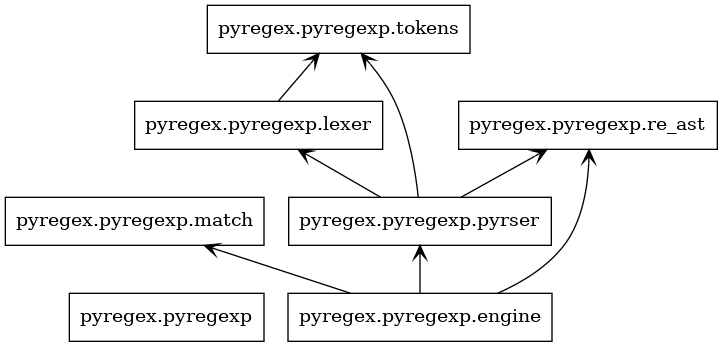
UML of pyregexp packages.#